Как парсить с помощью file_get_contents?

Как бы это удивительно не звучало, однако, с помощью встроенной функции file_get_contents можно парсить сайты так же успешно, как и с помощью curl.
В понимании новичков в PHP, скорее всего, отложилось, что file_get_contents предназначен только для считывания контента с локального файла. Однако, эта функция, имеет несколько больше обязанностей, чем, может показаться.
Помимо возможности считывания локальных файлов, можно аналогичным образом считывать удалённые файлы с другого сервера. И именно благодаря этой функции, мы и имеем возможность получать контент страницы по url-адресу, и парсить нужную информацию.
Так же, file_get_contents применяется и в API-запросах. Потому, информация из этой статьи, не только покажет, как парсить сайты с помощью file_get_contents, но, и на примере, покажет, как делать запросы к API сторонних сайтов.
Функция принимает 5 аргументов:
file_get_contents(file, include_path, context, offset, maxlen)
В данный момент для нас представляет интерес только первый - адрес файла (file), context - тоже важный аргумент для более тонкой настройки (подробнее почитать про контекст потока (context)).
Проще рассматривать это на примере. Чтобы это было интереснее, сделаем это на реальном сайте. Попробуем спарсить url всех картинок с главной страницы goodfon.ru:
$url = 'https://www.goodfon.ru';
$content = file_get_contents($url);
Если распечатать сейчас содержимое $content, то получим желаемую html-разметку
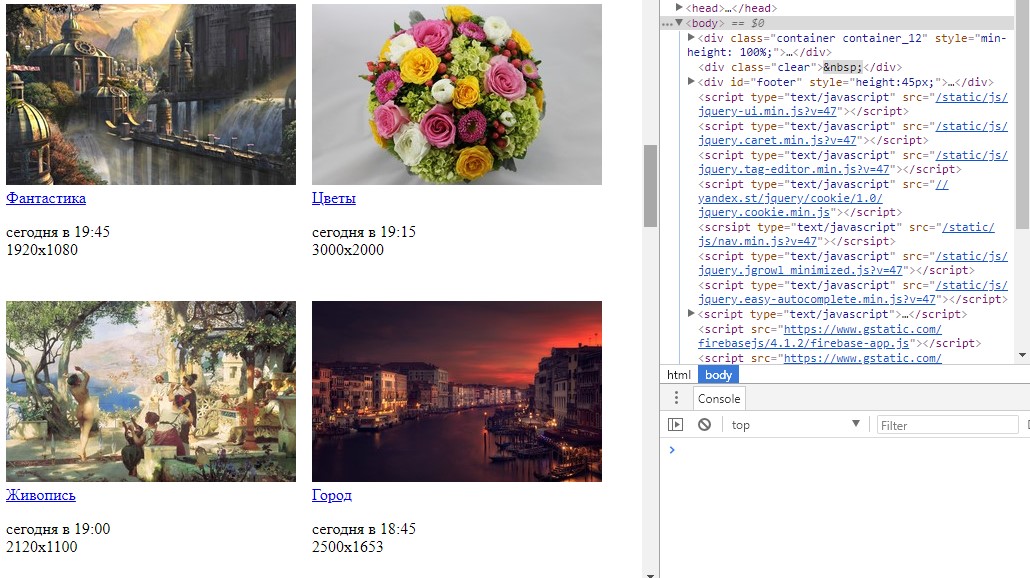
Как следует из статьи по основам парсинга, получается, что на 1/3 задачи мы уже выполнили, успешно сделав http-запрос, и получив корректный ответ.
Следующим нашим действием будет попытка парсинга полученной разметки. Прямо сейчас можно попытаться найти все картинки по регулярному выражению <img.*src="(.+)".*> однако, этот вариант не пройдёт, потому как, помимо интересующих нас картинок, разметка содержит картинки дизайна (фоны, иконки и прочие, что, для нас не является полезным контентом).
Ниже я опишу решение, которое не является универсальным для всех сайтов. Для того, чтобы найти решение по поиску нужных элементов, предварительно, нужно изучить разметку (классы, вложенность элементов, их id, и т.д.), и найти уникальные css-селекторы, которые соответствуют только нашим элементам (в данном случае, картинкам). И именно благодаря этим уникальный селекторам мы сможем понять, какой элемент является нужным. Я же, опишу основную идею, и подход, который поможет принять решение и выбрать правильный метод парсинга.
Сначала, нужно просмотреть исходный код в браузере (f12 в chrome) на странице goodfon.ru, выбрать один из элементов (картинку), и изучить, присутствуют ли в его тегах, или свойствах уникальные параметры. В нашем случае, повезло - каждой картинке, присваивается itemprop="thumbnail", что и отличает их других.
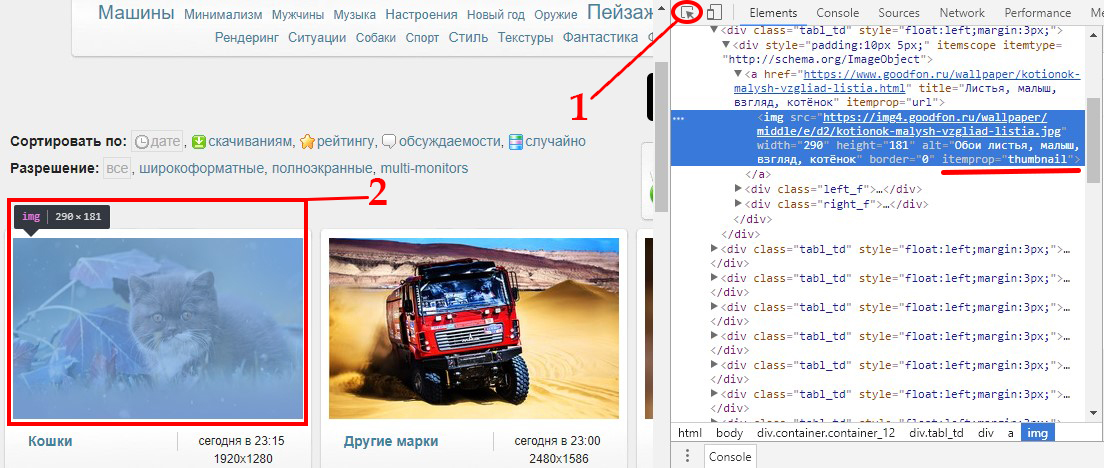
Новое регулярное выражение будет выглядеть так: <img.*src="(.+)".*itemprop="thumbnail">
И в результате запуска этого скрипта:
$url = 'https://www.goodfon.ru';
$content = file_get_contents($url);
preg_match_all('/<img.*src="(.+)".*itemprop="thumbnail">/U', $content, $match);
print_r($match[1]);
Получим ответ в виде url-адресов картинок:
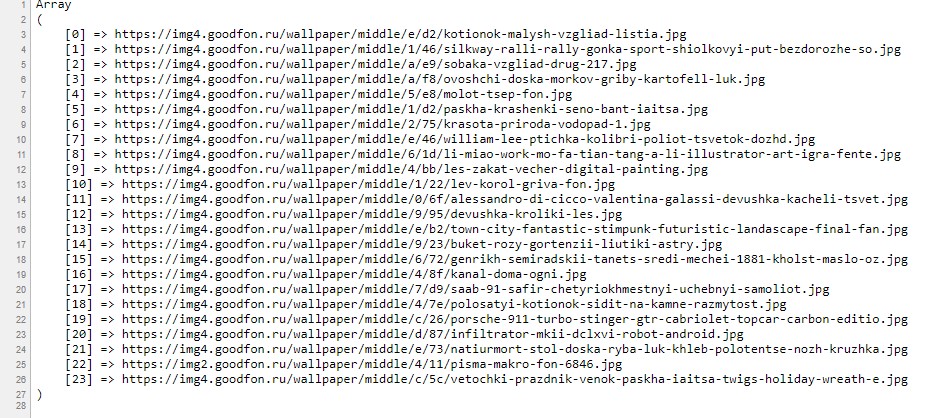
Что показывает то, что мы всё сделали верно, и парсер работает, как и задумано.
Улучшать этот парсер можно бесконечно: перейти на парсинг DOM-селекторов, парсить результаты с 10 страниц, сохранять URL-адреса в файл, скачивать изображение в папку и т.д.
Этот пример был продемонстрирован в учебных целях, потому всё достаточно поверхностно.
Дальше - будет интереснее и навороченнее.
Преимущества:
- встроенная функция, не требующая дополнительных пакетов для работы
- простота использования
Недостатки:
- allow_url_fopen должен быть включён на хостинге (на shared-хостингах, часто является отключённым)
- меньшая гибкость (в отличии от curl)
- невозможность работаты в несколько потоков
Так же, на примере Яндекс Переводчика, я сейчас покажу, как делать запросы к API сторонних сайтов. Как уже было рассмотрено на примере POST-запросов в статье по подмене контекста, сейчас будет тот же пример, только с отправкой данных GET-запросом.
Там, получив API-ключ, формировали данные для запроса:
$data = [
'text' => 'Привет мир?', //текст
'lang' => 'ru-en', //язык перевода с русского на английский
'key' => 'ВАШ КЛЮЧ' //API ключ, полученный ранее
];
Только теперь, нам нужно эти данные вписать в url запроса. Как и в прошлом случае, можно воспользоваться функцией http_build_query:
$url = 'https://translate.yandex.net/api/v1.5/tr.json/translate';
$url .= '?' . http_build_query($data);
//получим строку вида: https://translate...translate?text=..&key=...
$response = file_get_contents($url);
И в переменную $response получим результат.
В итоге, мы разобрали, как отправить APi запрос, на примере yandex translate API, как его обработать, и как парсить данные с сайта