ElasticSearch: что такое, как работать и где применять

Качественный поиск на вашем сайте - это не самая тривиальная вещь, которую можно придумать. Если ранее вы имели задачу по реализации поиска по базе данных, то должны понимать, что действительно, качественный поисковый алгоритм не так просто разработать. Ввиду того, что эта задача стоит перед разработчиками очень часто, а так же, эта задача не самая простая, существует много продвинутых решений, помогающих нам с решением этой проблемы. Благодаря качественно разработанному поиску вы улучшите опыт времяпровождения пользователей на вашем сайте. И в этом нам поможет Elasticseach. Поисковый алгоритм должен соответствовать 2 условиям:
- хорошая релевантность запросов
- высокая скорость поиска
Как раз, ElasticSeach удовлетворяет нас по этим 2 показателям, плюс, он имеет ещё много дополнительных функций и возможностей для того, чтобы сделать нашу жизнь ещё проще.
Что такое Elasticsearch и как он работает
Вот как сами разработчики говорят о своём продукте на сайте:
Elasticsearch - это распределённый поисковой и аналитический движок с REST-api, имеющий широкое применение и помогающий решить большой количество нетривиальных бизнес-задач.
Elasticsearch использует документо-ориентированную модель хранения данных, сохраняя всё в JSON-формате. Распределение и хранение информации основано на, так называемых индексах и типах. Их может быть большое множество. Вы можете думать о индексах как о базе данных в реляционных СУБД, а типы - как таблица этой БД. На просто примере сравнения, можете увидеть аналогии, построенные между базой данных и структурой хранения в Elasticsearch:
| MySQL | Базы дынных | Таблицы | Строки/Колонки |
| Elasticsearch | Индексы | Типы | Документы со свойствами |
Весомым преимуществом его является то, что этот поиск быстрый, масштабируемый и возвращает более релевантные запросы, чем, Mysql LIKE, например. Внедрение его в свой проект позволяет выполнять запросы действительно быстро, а благодаря легкой масштабируемости, такой поиск может быть расположен сразу на нескольких серверах, и хранить большое количество данных, выполняя параллельный поиск. Elasticsearch очень полезен при работе с большими данными, и делает работу при поиске по миллионным данным практически в реальном времени. Такова магия Elasticsearch.
Для того, чтобы установить Elasticsearch, рекомендую просмотреть эту статью, в которой были рассмотрены примеры установки на все операционные системы (в том числе, Docker и Homestead Vagrant).
Базовые понятия
Перед началом, хотелось бы рассмотреть подробнее, важные определения.
Для изучения Elasticsearch нужно ознакомиться с такими его базовыми понятиями:
Кластер
Кластер - это набор одного или более узлов, которые объединены под одним уникальным именем. Он поддерживает индексирование и поиск по всем узлам, которые ему пренадлежат. Кластер должен иметь уникальное имя (по умолчанию это elasticsearch). То есть, кластер полезен при масштабировании. Кластер объединяет в себе несколько независимо работающих серверов с Elasticsearch.
Узел (Node)
Узел - это единичный сервер, который является частью кластера. Узел хранит данные и учавствеет в индексировании и поиске данных.
Индекс
Индекс - это набор документов с похожими свойствами и структурой, который идентифицируется по уникальному имени (как и таблица в реляционной БД). Это имя используется для обращения к конкретному индексу, при добавлении в индекс, поиске, обновлении и удалении документов из него. В одном кластере может находится столько индексов, сколько пожелаете.
Документ
Документ это базовая единица информации, находящаяся в индексе. Информация документа хранится в формате JSON. Документ - как одна конкретная запись из реляционной БД.
Фрагмент (Shard)
Elasticsearch поддерживает возможность разделять индексы на фрагменты (shards). Каждый из них является полнофункциональным и независимым "индексом", который может быть частью узла внутри кластера. Это полезно, в случаях, когда индекс добавляется в один узел, который не будет занимать больше места, чем ему доступно. Индекс тогда разделяется между несколькими различными узлами. Кроме того, shards позволяют распределять и выполнять параллельные операции между этими фрагментами, повышая при этом производительность.
Replica
Elasticsearch позволяет вам сделать один или более копий ваших индексов, называемые копией фрагмента (replica shard), или просто replica. Это позволяет обеспечить высокую отказоустойчивость в случае сбоя узла и позволяет легко масштабировать поиск, поскольку поиск может выполняться параллельно на нескольких фрагментах.
Грубо говоря, реплика - это бекап данных, который сохранён на другом сервере. И в случае, если текущий сервер по каким-либо причинам отваливается, то данные берутся с запасного сервера.
Какие способы внедрения Elasticsearch в свой проект
При внедрении Elasticsearch в свой проект, существует несколько способов:
- Запустить его на локальной машине, на которой расположен ваш проект/вебсайт.
- Запустить его на отдельном сервере, например, на Amazon AWS Elasticsearch, или DigitalOcean. Там вам нужно выбрать характеристики железа и тариф, в зависимости от того, какие размеры и нагрузки ожидаются.
Как говорится на их сайте, чем больше ОЗУ, тем лучше работает Elasticsearch.
Добавление документа
Перед тем, как мы разработаем простое PHP-приложение, которое будет взаимодействовать с Elasticsearch, я покажу как добавлять документы в индекс, просто используя REST API, выполняя запросы из обычного HTTP-клиента:
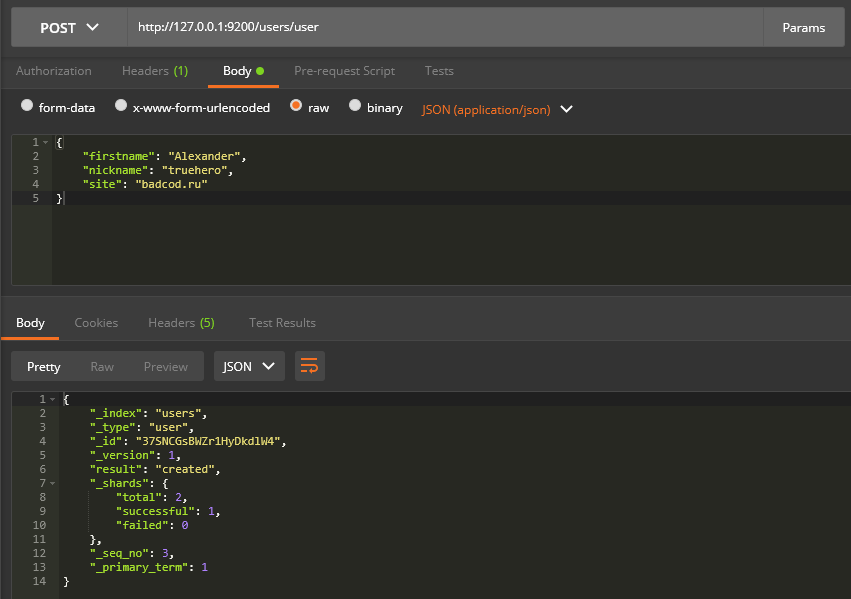
curl -H "Content-Type: application/json" -XPOST "http://127.0.0.1:9200/users/user" -d "{ \"firstname\":\"Alexander\", \"nickname\":\"truehero\", \"site\":\"badcode.ru\" }"
В текущем случае, экранирование кавычек в теле запроса
\"должно быть, чтобы на сервер отправился валидный JSON.
В этой команде я использовал curl, чтобы отправить POST запрос к серверу Elasticsearch.
Адрес, по которому обращаемся, состоит из таких параметров:

где users - указывает, под каким индексом (о котором вы можете думать, как о базе данных) мы хотим добавить документ. В случае, если такого индекса не существует, он будет создан автоматически.
user - это тип (о нём можете думать, как о таблице в базе данных), куда сохраняется документ. Этот документ хранится в виде JSON-а, который мы и передали в теле запроса { "firstname":"Alexander", "nickname":"truehero", "site":"badcode.ru" }, который состоит из 3 полей: firstname, nickname и site, и их переданных значений.
Для демонстрации процесса поиска ниже, добавим ещё несколько записей:
curl -H "Content-Type: application/json" -XPOST "http://127.0.0.1:9200/users/user" -d "{ \"firstname\":\"Ivan\", \"nickname\":\"vanya007\", \"site\":\"badcode.ru\" }"
curl -H "Content-Type: application/json" -XPOST "http://127.0.0.1:9200/users/user" -d "{ \"firstname\":\"Valya\", \"nickname\":\"vasya007\", \"site\":\"badcode.ru\" }"
Если вы не используете CURL, а хотите для этого использовать программу Postman, то для этого, нужно настоить удалённый доступ для Elasticsearch и после чего, сможете воспользоваться этим клиентом, указав ему нужные параметры
Поиск документов
Перед тем, как создавать более сложные запросы, удостоверимся, что предыдущие данные были успешно сохранены:
curl -XGET "http://127.0.0.1:9200/users/user/_search/?pretty=true"
Этот запрос вернёт все документы, типа user, индекса users. А указание параметра pretty=true означает, что ответ от сервера должен вернуться в отформатированном виде (с читабельными отступами):
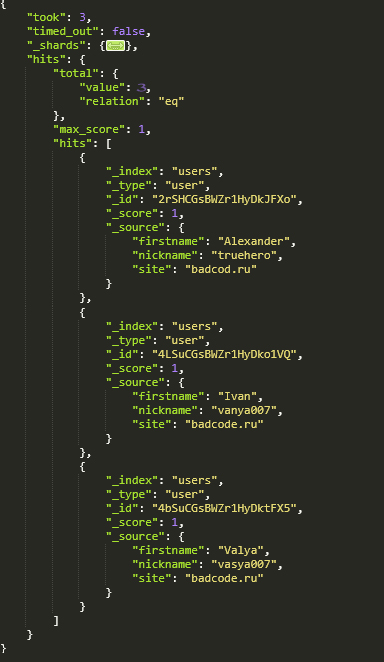
Как можете увидеть, все 3 пользователя были успешно добавлены. И, помимо указанных нами полей, Elasticsearch предоставляет информацию о том, сколько времени занял этот запрос (в миллисекундах), и какое количество результатов было получено, и дополнительные поля документа: индекс, тип и идентификатор.
Подключение и настройка ElasticSearch с PHP
Во второй части той статьи мы рассмотрим пример работы с Elasticsearch из PHP. В результате чего, напишем простой скрипт по добавлению данных в индекс из PHP, и их поиск.
Для выполнения запросов к серверу Elasticsearch из PHP, мы могли бы использовать обычный curl для всех запросов, как мы делали в первом секции перед этим. Однако более удобным вариантом будет использовать PHP библиотеку elasticsearch/elasticsearch, которую установим через composer.
composer require elasticsearch/elasticsearchПосле того, как composer установит библиотеку, в папке vendor появится папка elasticsearch.
Теперь, создадим файл idnex.php, чтобы проверить работу этой библиотеки:
<?php
// подключаем автозагрузчик composer-а
require __DIR__ . '/vendor/autoload.php';
use Elasticsearch\ClientBuilder;
// создаём клиент библиотеки elasticsearch для выполнения запросов
$client = ClientBuilder::create()
->setHosts(['localhost:9200']) // указываем, в виде массива, хост и порт сервера elasticsearch
->build();
$data = $client->search([
'index' => 'users',
'type' => 'user',
'body' => [
'query' => [
'match' => [
'site' => 'badcode.ru'
]
]
]
]);
echo '<pre>', print_r($data, true), '</pre>';
В строке ...->setHosts(['localhost:9200']) указываем, по какому адресу находится сервер Elasticsearch. Ввиду того, что он установлен локально на 9200 порту, то мы и указали localhost:9200.
Дальше, вызываем метод поиска, передав нужные параметры:
$data = $client->search([
'index' => 'users', // имя индекса
'type' => 'user', // тип
'body' => [
'query' => [
'match' => [
'site' => 'badcode.ru'
]
]
]
]);
Для текущего примера мы указали параметры для поиска, означающие, что нужно получить все документы, из индекса users, типа user, и которые имеют значение поля site равно badcode.ru (по прямому соответствию).
А строкой echo '<pre>', print_r($data, true), '</pre>'; мы просто печатаем ответ от сервера на страницу. Благодаря тегам <pre> ответ от сервера становится более читаемым и удобным для восприятия.

И здесь вы можете увидеть, что мы получили 2 результата, которые соответствуют истине.
Создание списка найденных результатов
Для завершения этой статьи, я обработаю полученные результаты от Elasticsearch, и сделаю удобный вывод полученных данных в HTML шаблоне.
Для начала, удалим строку, которая печатала полный ответ: echo '<pre>', print_r($data, true), '</pre>';.
После чего, пройдёмся по полученному массиву данных, и создадим на его основе свой, содержащий только нужные нам данные:
$results = array_map(function($item) {
return $item['_source'];
}, $data['hits']['hits']);
Я использовал функцию array_map для того, чтобы преобразовать массив с множеством ненужных мне данных, в удобный, содержащий только данные о найденных пользователях [firstname, nickname, site].
И, после, можем распечатать результаты в HTML-шаблоне:
foreach($results as $result) {
echo "User: {$result['firstname']} ({$result['nickname']}) - {$result['site']} <br>";
}
В итоге, получился такой результат:

Резюме
В этой статье я рассказал, что такое Elasticsearch, написал небольшой гайд по работе с ним, для чего он нужен, как делать индексы в elasticsearch, описал его базовые понятия и термины для чайников. Так же, показал, как работать с Elasticsearch из PHP, как добавлять документы, искать их, продемонстрировав примеры запросов, и как они строятся. А так, же, как обрабатывать ответ от Elasticsearch в PHP, как делать поиск.
Дальше будут более продвинутые примеры, агрегации, настройка анализаторов, работа с Laravel, массивами, связями и т.д.
А пока что, советую детальнее изучить документация.