Пишем быстрый PHP парсер (scraper)

Так сильно увлекаясь парсингом сайтов, я удивляюсь самому себе, насколько мало информации я публикую на эту тему. Сегодня я решил немного поправить эту несправедливость. В этой статье я хочу показать, как сделать быстрый парсер на PHP, в частности парсер фильмов с кинопоиска средствами PHP.
Примите к сведению, что при парсинге мы полагаемся на определённую DOM-структуру сайта, определённые css-селекторы в HTML-разметке страницы. Потому, держите в уме вероятность того, что структура сайта в будущем будет обновлена, и парсер, возможно перестанет работать. И, вероятно, с кодом из этой статьи случится то же самое, когда сайт-донор обновит разметку.
Большинство PHP-разработчиков, хоть раз в жизни делали парсер. Будь то с использованием file_get_contents, или curl, но, уверен, каждый хоть раз в жизни парсил информацию из Web-а. И это не удивительно, ведь очень часто появляется необходимость в копировании большого количества информации со сторонних сайтов, особенно для новых, пустых сайтов, нуждающихся в автоматическом наполнении.
Алгоритм парсинга аналогичен тому, что вы бы открыли нужный URL в браузере, просмотрели бы сайт, и скопировали бы нужную вам информацию себе. Но если таких действий нужно будет проделать несколько тысяч раз, то это становится довольно затруднительно. И, к счастью, это можно легко автоматизировать с помощью скриптов. В этой статье я покажу, как написать быстрый парсер, используя асинхронные запросы.
Зачем люди пишут парсеры
Немного отклонившися от курса этой статьи, на живом примере расскажу, где из популярных сайтов используется регулярный парсинг и наполнение с другого более популярного сайта.
Существует один сайт, уверен, на который вы натыкались в гугле при поиске решений проблем при программировании - qaru.site. И идея этого сайта как раз и строится на основу двух парсеров. Первый из которых копирует вопросы со всей информацией с популярного англоязычного сайта-аналога stackoverflow.com. А задача второго - переводить текст вопроса и ответов с английского на русский (с первого взгляда кажется, что это производится через Google Translate).
То, есть, если рассматривать роль парсера в проекте qaru.site, то, без раздумий можно утверждать то, что парсер в этом проекте - это 80% его успеха. Ведь, вместо того, чтобы развивать свой форум с нуля, просто было скопировано большое количество реальной информации с другого сайта. И из-за того, что эта информация в оригинале была на английском, то, со стороны поисковых систем её перевод расценивается как условно-полностью уникальный текст (невзирая на то, что перевод постов там сродни "я твой дом труба шатать").
Но, это только один пример, придуманный сходу. На самом же деле, парсеры используются почти в каждом проекте: для наполнения сайта данными, для актуализации и обновления. Потому, их применение достаточно широко, и интересно. Потому знать, как писать парсер на php нужно. А если вы ещё освоите многопоточный парсинг, то жизнь станет ещё проще ^^.
Задача
В этой статье я напишу простой WEB-парсер информации о фильме с Кинопоиска, который будет получать детали этого фильма: 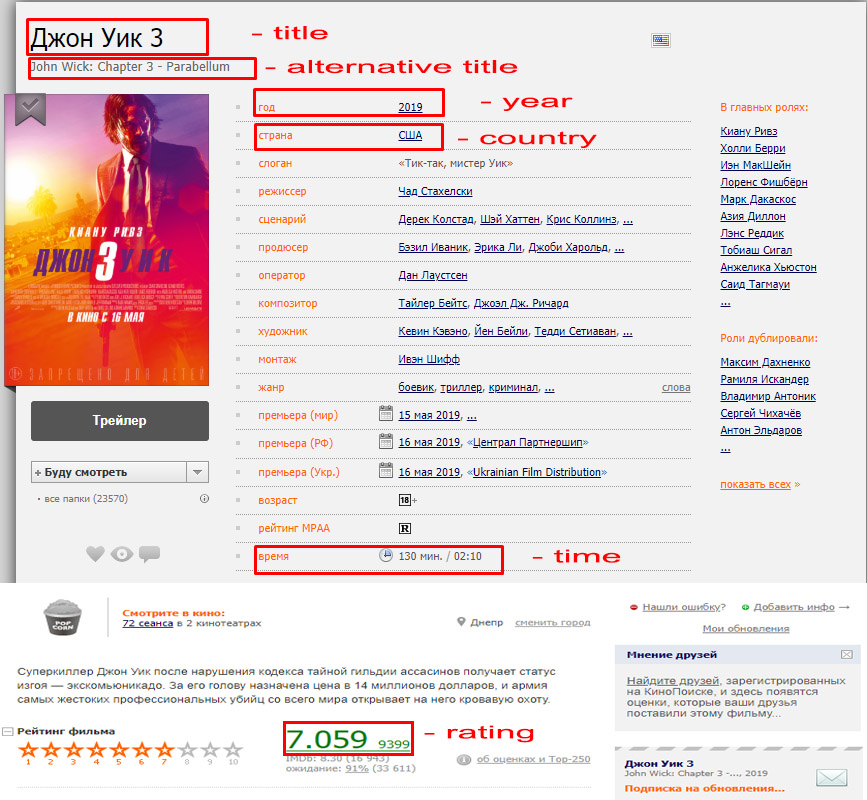
Почему я использую ReactPHP для выполнения асинхронных запросов? Если кратко - это быстрее. Если представить, что мы хотим спарсить все фильмы с первой страницы популярных фильмов, то для получения данных о всех фильмах понадобится выполнить 1 запрос на получение списка, и 200 запросов на получение подробной информации о каждом фильме отдельно. В итоге, 201 запрос, выполняя его в синхронном режиме, последовательно друг за другом может занять достаточно много времени.
И в противовес этому, представьте, что есть возможность запустить обработку всех этих запросов одновременно. И в этом случае, данные будут скопированы на порядок быстрее. Давайте попробуем.
Настройка проекта
Перед тем, как начать, с помощью композера нужно установить несколько зависимостей.
Сначала, установим асинхронный HTTP-клиент buzz-react. Это простой PSR-7 HTTP клиент, который поможет выполнять асинхронные HTTP-запросы.
composer require clue/buzz-reactДля того, чтобы из целой html-страницы получить определённые "куски" с нужной для нас информацией, используем библиотеку для парсинга по DOM-структуре. Я использую DiDOM
composer require imangazaliev/didomТеперь, можем начинать. Для начала, напишем такой код:
<\?php
require __DIR__ . '/vendor/autoload.php';
use Clue\React\Buzz\Browser;
$loop = React\EventLoop\Factory::create();
$client = new Browser($loop);Мы сделали задел проекта для начала, определили инстанс HTTP-клиента. Следующий шаг - выполнение запросов.
Делаем запросы
Интерфейс класса Clue\React\Buzz\Browser достаточно простой и прямолинейный. Имена методов соответствуют HTTP-методам, которые он выполняет: GET-метод соответствует методу get(), GET-post(), PUT-put() и т.д. И каждый из этих методов возвращает Promise (если вы знакомы с JavaScript, или ранее работали с ReactPHP, то это не должно вызвать у вас вопросов). Если вы не знаете, что это, то на даном этапе объяснения не имеют большого смысла, дальше будет пример, после которого всё станет понятно.
Для текущей задачи нам будет достаточно одного метода get($url, $headers = []):
// ...
$client->get('https://www.kinopoisk.ru/film/1009536/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
echo $response->getBody() . PHP_EOL;
});
В коде выше будет описана анонимная функция, которая после успешного запроса выведет HTML-разметку на экран. Эта функция принимает ответ экземпляра \Psr\Http\Message\ResponseInterface. В этой функции мы можем описать обработчик ответа, который вернёт из этого промиса (Promise) распарсенную информацию, без лишнего HTML-кода.
Как вы можете заметить, алгоритм парсинга достаточно прост:
- Делаем запрос и получаем промис.
- Пишем обработчик этого промиса.
- Парсим нужную информацию внутри этого обработчика.
- Если нужно, повторяем первый шаг.
Работа с DOM документа
Страница фильма, которую мы парсим не требует никакой авторизации. Если посмотреть на исходный код этой страницы, то можно увидеть, что все данные, за которыми мы охотимся, доступны внутри HTML. Иногда бывают случаи, когда анализ сайта, его противопарсинговые защиты, обход алгоритмов защиты и т.д. занимают на порядок больше времени, чем написание самого кода парсера.
Теперь, когда мы научились получать ответ (содержимое WEB-страницы), можем начать работу с DOM-ом этого документа. Для этого, как я и ранее писал, я буду использовать Didom, подробнее о котором вы можете почитать здесь.
Для начала работы, нужно создать экземпляр класса \DiDom\Document, конструктор которого принимает HTML-разметку.
$client->get('https://www.kinopoisk.ru/film/1009536/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$document = new \DiDom\Document($response->getBody()->__toString());
});
Внутри обработчика мы создали экземпляр класса \DiDom\Document, передав ему HTML-ответ, приведённый к строке. Теперь, нужно выбрать нужные данные, используя соответствующие CSS-селекторы.
Заголовки (Title, Alternative Title)
Заголовок может быть получен с тега h1 (который единственнный на всей странице).
$client->get('https://www.kinopoisk.ru/film/1009536/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$document = new \DiDom\Document($response->getBody()->__toString());
$title = $document->first('h1')->text(); // Джон Уик 3
});
Метод first($selector) ищет первый элемент, соответствующий указанному селектору. После чего, к найденного элемента вызывается метод text(), который возвращает текст, содержащийся в этом элементе. Навигация и парсинг DOM-дерева выглядит очень похожим с jQuery:
var title = $('h1').text();
Таблица параметров
Такие параметры фильма, как год, страна, слоган и т.д. находятся в таблице с классом info.
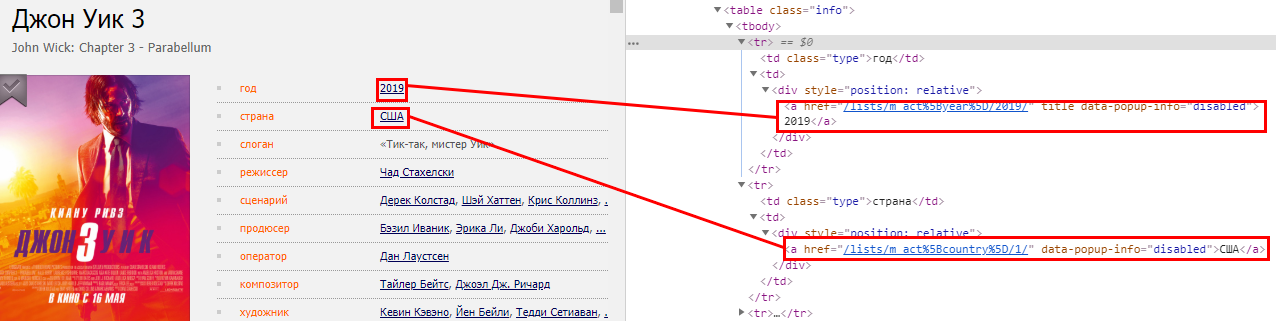
А ещё из разметки можно увидеть, что нужные нам параметры находятся во втором столбце (td) каждой из строк таблицы (tr). Но, нам не нужно сильно запариваться по поводу парсинга информации, так как можно увидеть, что в каждой строке таблицы есть только по одной ссылке, которые, как раз таки, и содержат внутри себя текст параметров.
Для этого, напишем код, получая сначала все строки таблицы, а потом обращаясь к ним по индексу:
$client->get('https://www.kinopoisk.ru/film/1009536/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$document = new \DiDom\Document($response->getBody()->__toString());
$title = $document->first('h1')->text(); // Джон Уик 3
$alternativeHeadline = $document->first('span.alternativeHeadline')->text();
$tableRows = $document->find('table.info tr');
$year = $tableRows[0]->first('a')->text(); // 2019
$country = $tableRows[1]->first('a')->text(); // США
});
Время и рейтинг (time, rating)
Информация о времени находится в той же таблице, которую парсили в прошлом шаге. Для получение данных, можно, как и в прошлом коде, обратиться по индексу:
//...
$time = $tableRows[16]->first('td.time')->text();Однако, изучив детальнее, можно увидеть, что у блока "время" есть уникальный идентификатор runtime, которым мы и воспользуемся.

И в этом случае, код будет выглядеть:
//...
$time = $document->first('td#runtime')->text(); // 130 мин. / 02:10И, аналогично поступим с рейтингом. Он, правда, не имеет тега id, однако, класс блога рейтинга уникальный, и не повторяется на странице, потому будем обращаться по нему:

//...
$rating = $document->first('span.rating_ball')->text(); // 7.059Итого, код парсера будет выглядеть так:
$client->get('https://www.kinopoisk.ru/film/1009536/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$document = new \DiDom\Document($response->getBody()->__toString());
$title = $document->first('h1')->text(); // Джон Уик 3
$alternativeHeadline = $document->first('span.alternativeHeadline')->text();
$tableRows = $document->find('table.info tr');
$year = $tableRows[0]->first('a')->text(); // 2019
$country = $tableRows[1]->first('a')->text(); // США
$time = $document->first('td#runtime')->text();
$rating = $document->first('span.rating_ball')->text();
});
Написание класса парсера
Теперь пришло время собрать все части спаршеных данных вместе. Логина по выполнению запроса может быть помещена в отдельную функцию/класс, а так же, нужно добавить более гибкую функциональность, добавив возможность указания разных URL-адресов. Для этого, создадим класс KinopoiskParser
class KinopoiskParser {
/**
* @var Browser
*/
private $client;
/**
* @var array
*/
private $data = [];
public function __construct(Browser $client)
{
$this->client = $client;
}
public function parse(array $urls)
{
foreach ($urls as $url) {
$this->client->get($url)->then(
function (\Psr\Http\Message\ResponseInterface $response) {
$this->data[] = $this->parseDOM((string)$response->getBody());
});
}
}
private function parseDOM(string $html)
{
$document = new \DiDom\Document($html);
$title = $document->first('h1')->text(); // Джон Уик 3
$alternativeHeadline = $document->first('span.alternativeHeadline')->text();
$tableRows = $document->find('table.info tr');
$year = $tableRows[0]->first('a')->text(); // 2019
$country = $tableRows[1]->first('a')->text(); // США
$time = $document->first('td#runtime')->text();
$rating = $document->first('span.rating_ball')->text();
return [
'title' => $title,
'alternative_title' => $alternativeHeadline,
'year' => $year,
'country' => $country,
'time' => $time,
'rating' => $rating,
];
}
public function getData()
{
return $this->data;
}
}
Класс KinopoiskParser принимает объект Browser как зависимость в свой конструктор. Функциональность этого класса достаточно проста: в нём существует 2 метода: parse() - который принимает массив URL-адресов на фильмы, и getData(), который возвращает массив всех спаршенных данных о фильмах.
Теперь, наконец-то, можем попробовать этот парсер в действии:
//...
$loop = React\EventLoop\Factory::create();
$client = new Browser($loop);
$parser = new KinopoiskParser($client);
$parser->parse([
'https://www.kinopoisk.ru/film/1009536/',
'https://www.kinopoisk.ru/film/326/',
'https://www.kinopoisk.ru/film/435/',
'https://www.kinopoisk.ru/film/2360/',
]);
$loop->run();
var_dump($parser->getData());
В этом коде мы создали объект парсера, передали его методу URL-адреса для парсинга, после чего, запустили обработчик цикла событий. События будут обрабатываться до тех пор, пока все запросы не будут выполнены, и результаты, в которых нуждаемся, не спаршены с HTML-разметки. Как результат, эти запросы выполняются параллельно, потому, итоговое время выполнения скрипта будет равно самому медленному из наших запросов.
Результат будет выглядеть примерно так:
array(4) {
[0]=>
array(6) {
["title"]=>
string(19) "Король Лев"
["alternative_title"]=>
string(13) "The Lion King"
["year"]=>
string(4) "1994"
["country"]=>
string(6) "США"
["time"]=>
string(18) "88 мин. / 01:28"
["rating"]=>
string(5) "8.773"
}
[1]=>
array(6) {
["title"]=>
string(32) "Побег из Шоушенка"
["alternative_title"]=>
string(24) "The Shawshank Redemption"
["year"]=>
string(4) "1994"
["country"]=>
string(6) "США"
["time"]=>
string(19) "142 мин. / 02:22"
["rating"]=>
string(5) "9.112"
}
[2]=>
array(6) {
["title"]=>
string(23) "Зеленая миля"
["alternative_title"]=>
string(14) "The Green Mile"
["year"]=>
string(4) "1999"
["country"]=>
string(6) "США"
["time"]=>
string(19) "189 мин. / 03:09"
["rating"]=>
string(5) "9.062"
}
[3]=>
array(6) {
["title"]=>
string(18) "Джон Уик 3"
["alternative_title"]=>
string(33) "John Wick: Chapter 3 - Parabellum"
["year"]=>
string(4) "2019"
["country"]=>
string(6) "США"
["time"]=>
string(19) "130 мин. / 02:10"
["rating"]=>
string(5) "7.037"
}
}
Дальше вы можете продолжать писать парсер как угодно: разделив его на несколько файлов, добавить запись результатов в базу данных. Главная цель этой статьи была показать, как выполнять асинхронные запросы в PHP и обрабатывать ответ с помощью DOM-парсинга.
Добавление таймайта
Этот парсер может быть немного улучшим путём добавление таймаута на выполнение запроса. Просто, что будет, если самый медленный из запросов будет слишком медленным? И вместо того, чтобы ждать его завершения, мы можем указать таймаут - максимальное время, за которое он может отработать. Иначе же, если он не впишется в рамки этого таймаута, каждый из таких медленных запросов будет отменён. Для реализации такого функционала мы будем использовать встроенные возможности ReactPHP.
В чём идея:
- Получить промис запроса.
- Задать таймер.
- Когда время таймера наступит - отменить выполнение промиса.
Для этого, немного модифицируем код класса парсера KinopoiskParser, добавив в конструктор зависимость от \React\EventLoop\LoopInterface:
//...
class KinopoiskParser
{
// ...
/**
* @var \React\EventLoop\LoopInterface
*/
private $loop;
public function __construct(Browser $client, LoopInterface $loop)
{
$this->client = $client;
$this->loop = $loop;
}
}
После чего, модифицируем метод parse() так, чтобы он мог принимать таймаут.
//...
class KinopoiskParser
{
// ...
public function parse(array $urls, $timeout = 5)
{
foreach ($urls as $url) {
$promise = $this->client->get($url)->then(
function (\Psr\Http\Message\ResponseInterface $response) {
$this->data[] = $this->parseDOM((string)$response->getBody());
});
$this->loop->addTimer($timeout, function() use ($promise) {
$promise->cancel();
});
}
}
}
Если аргумент $timeout не будет передан, то будет применён таймаут по-умолчанию - 5 секунд. И, в случае, когда запрос не успевает отработать за указанное время, то этот промис отменяется. В текущем случае, все запросы, которые будут занимать больше времени, чем 5 секунд будут отменены. В случае же, если промис находится в режиме settled, то есть, когда запрос успешно выполнен, метод cancel() не создаст никакого эффекта.
Для примера, если мы не желаем ждать дольше, чем 3 секунды, напишем код:
//...
$parser->parse([
'https://www.kinopoisk.ru/film/1009536/',
'https://www.kinopoisk.ru/film/326/',
'https://www.kinopoisk.ru/film/435/',
'https://www.kinopoisk.ru/film/2360/',
], 3);
Некоторые сайты не любят людей, парсящие их ресурс, и пытаются бороться с ними. Когда вы делаете парсинг для личных целей, при небольшом количестве запросов - ничего страшного. Но, если попробовать выполнить сотни параллельных запросов с одного IP - вы можете натолкнуться на проблемы. Сайту может не понравиться то, что вы делаете запросы слишком часто и много, и, скорее всего, заблокирует вас. В этом случае вам очень пригодятся прокси. В следующей статье я как раз и опишу процесс работы с прокси с этим клиентом в асинхронном режиме.
Резюме
В этой статье я показал, как работать с ReactPHP, показал примеры работы с ним, реализовав пример простого php парсера кинопоиска. Так же, в этой статье было рассмотрено, как парсить html на php, с помощью php dom парсера DiDOM, который является лучшим DOM-парсером на PHP. К слову, DiDOM - это отличная замена всем известного php simple dom parser-а. Надеюсь, что теперь вы без проблем сможете написать парсер контента собственными руками на php. И, полностью освоив материал этой статьи, выполняя запросы асинхронно, вы значительно прибавите в скорости и качестве парсеров.
Хорошего парсинга.
Честно говоря, кинопоиск - не самый удачный ресурс для демонстрации парсинга данных, ввиду того, что он огрантчивает IP при частых запросах. Но, хочу подчеркнуть, что концепция этой статьи как раз не приследует цель написать парсер кинопоиска. А главная цель - демонстрация алгоритма, по которому разрабатываются парсеры, а так же, как разработка парсеров ложится на асинхронный код.