Australian Open 2020: прогнозирование результатов матчей с помощью нейроной сети на python

Если вы любитель тенниса, вы, наверное, с нетерпением ждали открытия Australian Open 2020 и пытались угадать, кто же займет первое место в этом турнире. А если вы, как и я, помешаны на статистике и анализе, то, возможно, вас заинтересует тема того, как мы можем использовать статистические данные для составления прогнозов и предсказания результатов.
Код нейронной сети написан на Python. По тематике блога больше подходил бы PHP, или JavaScript (но это ещё будет). Но всё же, с удобным запуском python-а у себя на компьютере вам может помочь Docker.
Если вы любитель тенниса, вы, наверное, с нетерпением ждали открытия Australian Open 2020 и пытались угадать, кто же займет первое место на этом турнире. А если вы, как и я, помешаны на статистике и анализе, то, возможно, вас заинтересует, как мы можем использовать наборы данные и нейронные сети для прогноза при составлении предсказаний.
В этой статье будет приведен обзор рабочего процесса и методологии, которую я использовал для составления своих прогнозов. Этот проект реализован с той же задачей, что и Betfair's 2019 AO Datathon, которая заключается в том, чтобы сделать прогнозы по всем возможным исходам матчей для мужского дивизиона, только для Australian Open 2020. Моя методология в значительной степени опирается на работу специалистов Betfair по данным, в частности на заметки Qile Tan, с которыми вы можете познакомиться здесь. Правда, я немного переделал его код, чтобы он соответствовал моей задаче, и внёс несколько модификаций в некоторые разделы, однако, в своей основе, всё осталось нетронутым. Если вы хотите сразу же изучить сам код, который был написан, то можете перейти в репозиторий и детально всё просмотреть.
Отказ от ответственности: я не получаю спонсорскую помощь от каких-либо букмекерских контор, и если вы решите использовать мои данные для своих собственных стратегий предсказаний исходов матчей, то вы сами несёте ответственность за любые прибыли или убытки, которые можете понести.
Данные
Данные, которые мы будем использовать для обучения модели, были получены из пакета R 'Deuce', написанного Skoval. Эта библиотека парсит теннисные данные из различных источников, включая репозиторий GitHub Джеффа Сакмана. Насколько я знаю, эти данные общедоступны, так что вы свободно можете сами поиграть с ними.
Либо же, чтобы не использовать стороннее ПО, можете просто скачать нужный сет данных с репозитория JeffSackmann/tennis_atp
Каждая строка содержит информацию о конкретном матче: имя победителя и проигравшего, их ранги, страна происхождения, а также различные статистические данные об уровне матча, количестве выигранных игр, выигранных очков, сколько раз были совершены ошибки и т.д.
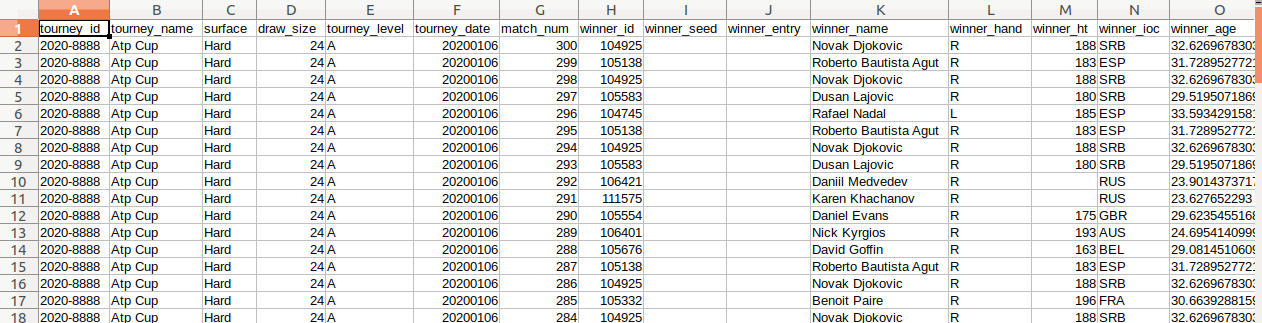
Первым шагом перед тем, как мы сможем перейти к созданию модели машинного обучения, является подготовка и очистка данных для качественного "скармливания" нашей моделе. Нам нужно будет распарсить счёт игры, сгруппировать возвращаемые данные и заполнить недостающие значения. Здесь я не буду подробно останавливаться на деталях, но вы можете посмотреть весь код в GitHub, если хотите увидеть код.
Какая задача стоит перед нами
Перед тем, как углубиться в машинное обучение, нам необходимо прийти к пониманию того, чего именно мы пытаемся достичь. Моя цель - предсказать результаты всех возможных матчей Australian Open 2020, прежде, чем начнётся сам турнир.
Предсказания будут производиться на основе статистики игроков, доступной до начала турнира. Например, если Надаль будет пересекаться с Федерером, то мы хотим предсказать, кто из них победит, но мы также хотим предсказать, как он сыграет с Джоковичем, Медведевым, Циципасом и всеми остальными игроками турнира. То же самое мы хотим сделать и с Федерером и предсказать, кому он вероятно проиграет в этом турнире. Затем мы повторим этот процесс еще раз для всех остальных участников.
Отметим две вещи:
- Во-первых, не все матчи, для которых мы делаем прогнозы, будут осуществлены. Федерер может проиграть в первом же раунде турнира, но мы всё равно будем делать прогнозы на его матчи с остальными игроками турнира на достаточно вероятный случай, если он всё-таки останется в игре. То же самое касается относительно неизвестного игрока, как Майкл Ммох, есть большая вероятность того, что он вылетит раньше. Но мы не можем делать на это 100% ставку, так что нам всё равно придётся делать прогнозы на его матчи против других игроков.
- Во-вторых, мы не будем пересчитывать предсказания во время игр, или после них, после завершения каждого из матчей турнира, мы не сможем учесть результаты выступлений в предыдущих раундах, чтобы обновить наши прогнозы на более поздние раунды. Прогнозы будут зависеть от статистики, доступной до начала турнира.
Но, в любом случае, мы должны тщательно определить, что является целевой переменной. Например, при непосредственном сравнении Джоковича и Надаля мы, скорее всего, спросим себя, кто выиграет? Проблема с формулировкой вопроса такова, что есть две возможные цели, которые мы можем смоделировать: вероятность того, что Надаль победит, или вероятность того, что победит Джокович.

Наш процесс моделирования становится более конкретным, если мы называем Джоковича как player_1, Надаль player_2 а целевым результатом является вероятность победы player_1.
Если вы хотите предсказать вероятность того, что Nadal выиграет, вы можете просто вычислить 1 - probability_player_1_wins, или поменять порядок следования player_1 и player_2 (обратите внимание, что эти два метода не совсем эквивалентны! Немного подробнее об этом позже).
Для тренировки и предсказания я выбрал оба сценария, первый из них, когда player_1, поставлен на выигрышную позицию, и обратный случай, когда уже player_2 поставлен на выигрышную позицию.
В своих заметках Тан случайным образом распределяет порядок так, чтобы в любом матче был шанс 50/50, что player_1 является победителем. Мой метод отличается тем, что для данного матча я включаю оба случая, а не просто случайный выбор.
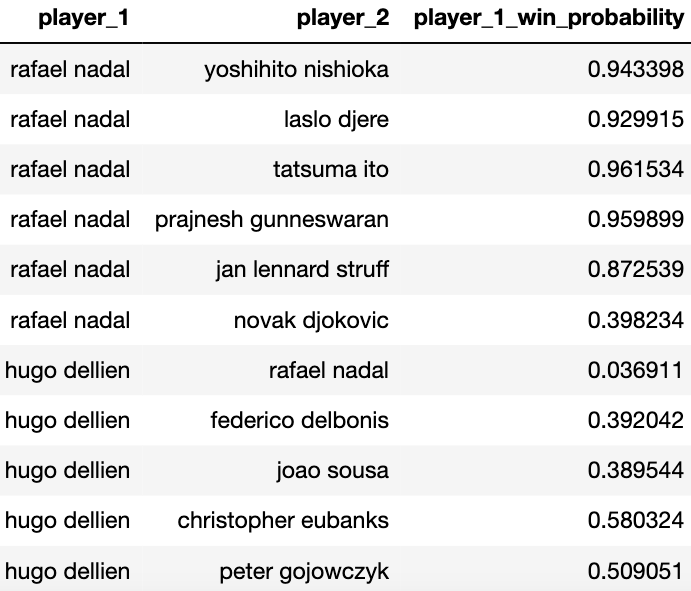
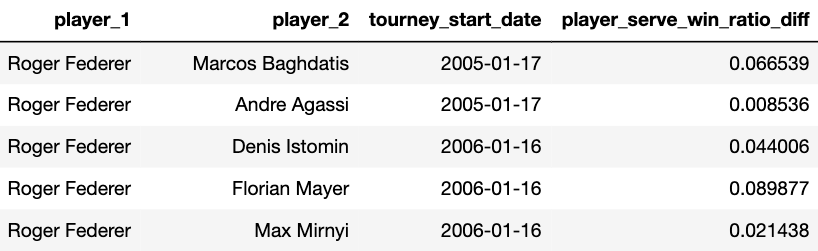
Чтобы помочь вам визуализировать происходящее, вот пример моих окончательных прогнозов. Обратите внимание, что Рафаэль Надаль выступает и как player_1, так и как player_2.
Функции, которые мы будем использовать для наших прогнозов, будут представлять собой разницу в средней статистике каждого игрока за предыдущие х матчей. Например, если мы рассматриваем матч Александра Зверева как player_1 и Стефаноса Циципаса как player_2, то для Александра Зверева мы хотим усреднить его статистику (например, процент выигранных партий) по последним 10 матчам, допустим, это число 0.63. То же самое мы сделаем и для Стефаноса Циципаса, допустим, его средний коэффициент выигрыша в матчах - 0.68. Отметим, что это усредненное значение по матчам, в которых каждый игрок участвовал индивидуально, а не по их общим предыдущим поединкам.
Возьмем разницу между двумя характеристиками игроков, 0.63-0.68 = -0.05 и используем ее как характеристику для прогнозирования того, выиграет ли player_1 (Александр Зверев). Так как это отрицательное число, то мы, естественно, ожидаем, что шансы будут слегка уравновешены с Зверем (все остальные равны). Мы можем сделать это для множества других статистических данных игроков, таких как ранг игрока, процент выигранных первой и второй подачи или процент выигранных ответных очков. Вот пример того, как это может выглядеть:

Преобразование данных
Теперь мы имеем структуру, по которой данные будут группироваться, и, которые мы будем использовать для обучения и тестирования моделей. Теперь нам нужно преобразовать "сырые" данные в удобный для дальнейшего использования в нейронке формат. Эта часть не особенно интересна, на самом деле это довольно утомительная и кропотливая работа, но именно она делает проблему уникальной и отличает её от обычных соревнований или дата-марафонов по Kaggle.
Первым шагом будет преобразование данных к нужному формату, чтобы для конкретного матча у нас будет статистика игроков как для победителя, так и для проигравшего, в отдельных строках. Затем нам нужно будет преобразовать необработанную статистику матчей игроков из абсолютных значений в относительные соотношения. Это важно, так как абсолютное значение статистики игрока зависит от длительности матча.
Например, предположим, что Федерер сыграет лучший из 3-х матчей против Кирьоса и обыграет его 6-4, 7-5. Всего Федерер выиграл 13 партий. Если Джокович выиграет эпическую 5-ю партию у Нишикори 7-6, 3-6, 5-7, 6-2, 7-6, то он выиграет в общей сложности 28 партий, более чем в два раза больше, чем Федерер. Это несправедливое сравнение, так как мы сравниваем лучший матч из 3 партий с лучшим из 5. Больше смысла имеет сравнивать их коэффициенты выигрыша в игре. Для Федерера коэффициент выигрыша в игре (6+7)/(6+4+7+5) = 0.59, для Джоковича коэффициент выигрыша в игре 0.51. Сравнение этих двух коэффициентов более разумно, чем использование итоговых значений.

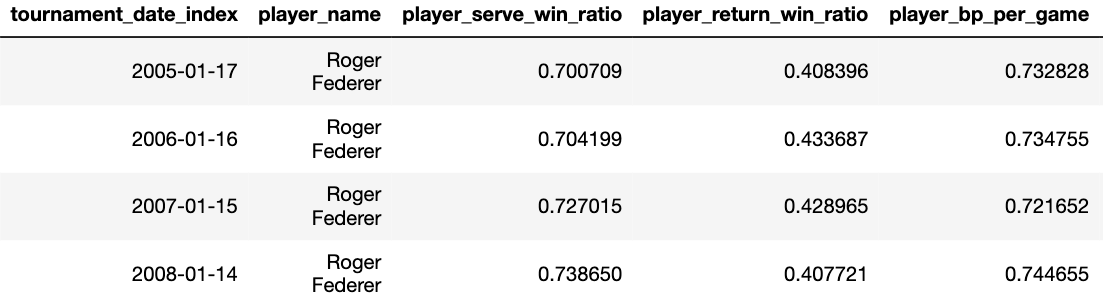
Следующим важным шагом будет суммирование статистики по данному игроку за предыдущее х количество матчей перед данным турниром. Хотя это кажется довольно интуитивно понятным, написание кода для этого несколько сложно. Я внес некоторые незначительные изменения в код Тана, но по большей части, оставил код без изменений. Обратите внимание, что мы будем создавать группировки только для Australian и US Open, чтобы сэкономить время на вычислениях, а также потому, что другие турниры, такие как Уимблдон и Роланд Гаррос, имеют разную динамику (подробнее об этом позже). Это нужно будет повторить для всех игроков в нашем наборе данных по всем турнирам Australian и US Open с 2000 по 2019 год (и на 2020 год).
Вот как будет выглядеть часть результатов для Роджера Федерера:
Эти показатели должны быть объединены с данными матча, ключами, которые будут однозначно идентифицировать нашу группу данных, будет дата турнира и имя игрока как для player_1, так и для player_2:
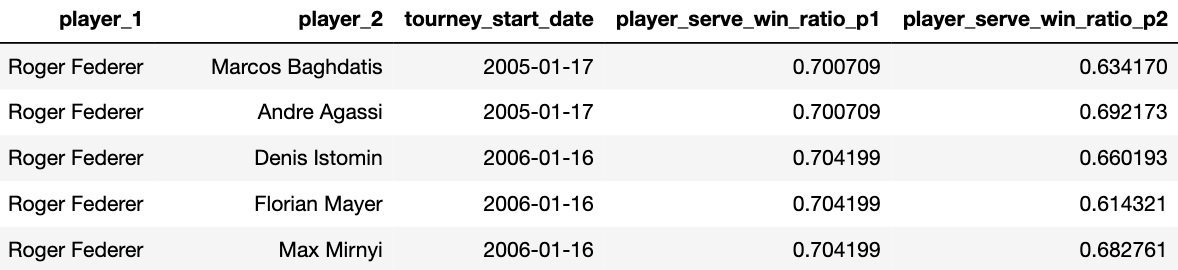
Заметьте, что у Федерера, его сводная статистика до данного турнира остаётся неизменной. Статистика для player_2 также останется постоянной, но он будет в паре с разными игроками, которые влияют на изменение этих параметров в каждом матче. Мы также возьмем различия между агрегатами player_1 и player_2, чтобы уменьшить количество функций и, следовательно, наше время вычисления. Интуитивно это работает, потому что, выиграет ли Федерер матч, зависит от того, насколько хорош его соперник по сравнению с ним.
Моделирование
Со всеми этими данными мы можем перейти к самой увлекательной части (помимо части наблюдения за работающей и успешно предсказывающей моделью) - обучения нашей модели! Для нашей модели я выбрал классификатор xgboost со следующими настройками:
model = XGBClassifier(
objective = "binary:logistic",
n_estimators = 300,
learning_rate = 0.02,
max_depth = 6
)
eval_set = [(X_val, y_val)]
model.fit(X_train,
y_train,
eval_set = eval_set,
eval_metric="auc",
early_stopping_rounds = 20)
Нам также нужно будет разделить данные на тренировочные и данные для тестирования (валидации) модели, чтобы предотвратить перегрузку xgboost. Я выбрал простое разделение данных: тренировочные по турнирам Australian и US Open в 2000-2017 гг. и валидацию на одних и тех же турнирах в 2018-2019 гг.
Также очень важно, чтобы мы не включали матчи ни с Уимблдона, ни с Открытого чемпионата Франции, так как стили игры будут заметно различаться в зависимости от поверхности корта. Например, при использовании глиняных кортов на French Open мяч отскакивает выше, но движется медленнее, что привносит дополнительную погрешность. Кроме того, схемы движения и ходьба игроков будут гораздо более скользкими из-за поверхности.
Аналогичный аргумент можно привести и для Уимблдона. Где травяное покрытие корта означает, что мяч движется быстрее, из-за чего, вероятность выиграть свою подачу повышается.
Подключив наши тренировочные и валидационные сеты данных в модель xgboost, мы получаем окончательную валидацию AUC со значением в 0,78, имея приличное количество возможностей для прогнозирования.
Stopping. Best iteration:
[147] validation_0-auc:0.782506
Пока я создавал множество дополнительных функций, я забраковывал несколько их них, так как некоторые, казалось бы, мешали работе модели. Для анализа вклада функций в предсказательную мощность мы можем использовать встроенный метод feature_importances_. Он, по сути, вычисляет долю времени, в течение которого функция появляется в дереве решений. Чем больше она появляется, тем больше вероятность того, что она будет сильным фактором точности прогнозирования. Подробнее об этом можно прочитать здесь.
pd.Series(model.feature_importances_, index=X_train.columns).sort_values(ascending=False)
player_log_rank_diff 0.617868
player_game_win_ratio_diff 0.109231
player_point_win_ratio_weighted_diff 0.080940
player_serve_win_ratio_diff 0.075152
player_rank_diff 0.060499
player_return_win_ratio_diff 0.056310
Неудивительно, что самой существенной характеристикой, определяемой xgboost, является разница в рангах игроков. Это также подтверждается важностью перестановки:
perm = PermutationImportance(model).fit(X_val, y_val)
eli5.show_weights(perm, feature_names = X_val.columns.tolist())

Важность пермутации, по сути, заключается в том, что она включает в себя перестановку в случайном порядке очередности измерений, а также в том, как она влияет на точность прогнозирования. Если точность резко снижается, то это хороший индикатор того, что данная функция была действительно важна, если она не сильно меняется, то эта функция, вероятно, не важна для вашей модели. Вы можете узнать больше здесь.
Делаем прогнозы
Учитывая, что большая часть инфраструктуры уже заложена, делать прогнозы теперь относительно просто. На этапе трансформации данных мы должны были создать агрегаты для всех игроков до начала турнира Australian Open 2020. Аналогичным образом, они должны были быть объединены с данными, полученными от нас, путем сопоставления по имени игрока (как для player_1, так и для player_2) и дате проведения турнира (2020-01-15). Принимая во внимание различия, подключаясь к нашей модели и соединяя прогнозы обратно в файл данных, вот что мы можем ожидать:
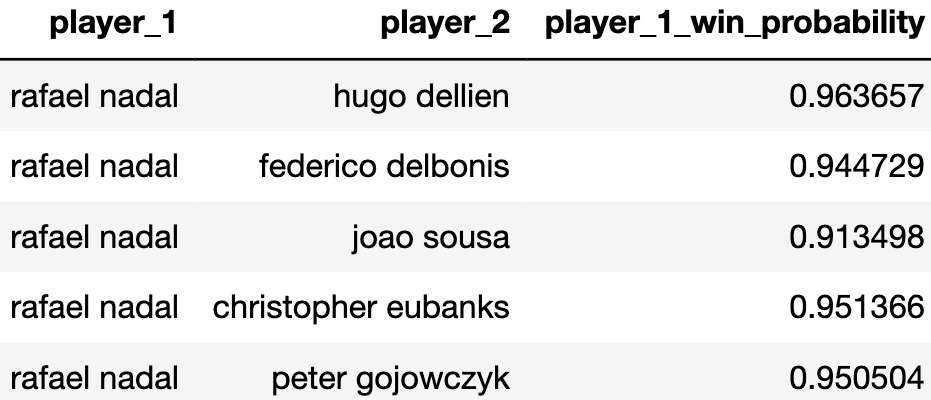
Сортируя игроков по среднему коэффициенту выигрыша, мы можем получить хорошее представление о том, кто, скорее всего, займет первое место:
atp_pred_submission.groupby('player_1')['player_1_win_probability'].agg('mean').sort_values(ascending=False).head(10)
novak djokovic 0.923752
roger federer 0.901148
rafael nadal 0.898214
dominic thiem 0.835166
daniil medvedev 0.804219
stefanos tsitsipas 0.795601
alexander zverev 0.786144
gael monfils 0.760937
diego sebastian schwartzman 0.748177
roberto bautista agut 0.745087
Идеи для улучшения
Во время работы над этим проектом было несколько вопросов, которые я не успел полностью решить. Как уже упоминалось ранее, замена порядка игроков и принятие 1-ой вероятности выигрыша конкретного игрока не совсем эквивалентны. Вот пример того, что я имею в виду:

При близком значении предсказанные вероятности не складываются точно до 1: 0.398234 + 0.606266 = 1.0045. Очевидным решением является их нормализация путем деления на 1.0045, однако код, реализующий это в форме, используемой xgboost, может быть довольно сложным для написания.
Дополнительной проблемой является выбранная мною стратегия проверки. В идеале я бы хотел использовать стратегию с прямыми связями, но еще не успел её разработать.
Другой вопрос - как следует учитывать турниры более низкого уровня? Хотя мы и включаем в них наши средние показатели, но должны ли мы также проводить агрегирование перед каждым из этих турниров и включать их в наши тренировочные и валидационные сеты?
Кроме того, набор данных Deuce не был обновлен, чтобы включить в него матчи первых двух недель 2020 года, такие как Кубок ATP и ряд других 250 или 500 турниров уровня по Австралии и Новой Зеландии. Наши агрегированные данные будут немного устаревшими, что не будет должным образом отражено в наших валидационных оценках, поскольку они содержат актуальные данные.
Но, ввиду того, что этот чемпионат уже прошел, у меня нет времени, чтобы непредвзято изучить эти вопросы. Возможно, это можно с этим можно будет разобраться для будущих событий.
Резюме
В этой статье я показал идею того, как можно создать собственную модель предсказаний исходов на спортивные события. Это больше информативная статья, демонстрирующая подход и стратегию мышления при решении подобных задач. От себя скажу, что нейронные сети - это чистая математика, и применять нейронные сети для полноценного прогнозирования не имеет так много смысла, как может показаться. Так как очень часто статистика просто не работает: случаются апсеты, андердоги побеждают фаворитов, и это невозможно предвидеть. В жизни слишком много подобной метафизики, чтобы полностью полагаться на нейронную сеть ^^.